
As a reminder, the key to establishing genuine connections between ancient languages is not finding a bunch of random words that can appear to be related, but establishing meaningful relationship with many examples of consistent sound changes. Here is an excerpt from Wikipedia's article on the "Comparative Method" describing how to establish legitimate connections:
Step 2, establish correspondence sets
The next step involves determining the regular sound-correspondences exhibited by the lists of potential cognates. For example, in the Polynesian data above, it is apparent that words that contain t in most of the languages listed have cognates in Hawaiian with k in the same position. This is visible in multiple cognate sets: the words glossed as 'one', 'three', 'man', and 'taboo' all show this relationship. This situation is termed a regular correspondence between k in Hawaiian and t in the other Polynesian languages. Similarly, in those data a regular correspondence can be seen between Hawaiian and Rapanui h, Tongan and Samoan f, Maori ɸ, and Rarotongan ʔ.
Mere phonetic similarity, as between English day and Latin dies (both with the same meaning), has no probative value.[31] English initial d- does not regularly match Latin d-[32]—it is not possible to assemble a large set of English and Latin non-borrowed cognates such that English d repeatedly and consistently corresponds to Latin d at the beginning of a word—and whatever sporadic matches can be observed are due either to chance (as in the above example) or to borrowing (for example, Latin diabolus and English devil—both ultimately of Greek origin[33]). English and Latin do exhibit a regular correspondence of t- : d-[32] (where the notation "A : B" means "A corresponds to B"); for example,[34]
English ten two tow tongue tooth Latin decem duo dūco dingua dent-
If there are many regular correspondence sets of this kind (the more the better), then a common origin becomes a virtual certainty, particularly if some of the correspondences are non-trivial or unusual.[21]
This is at the heart of what Stubbs has done, presenting extensive data on widespread, consistent sound changes that link cognates between Uto-Aztecan languages and three Old World languages (that happen to have Book of Mormon ties). Many are non-trivial, detailed, involve lengthy words and sometimes surprising parallels in meanings and multiple meanings. But Rogers seems to treat this work as amateur excitement over chance parallels.
Suppose, for example, that the German had gone completely extinct a couple hundred years ago and only now had scholars recovered and deciphered a handful of texts. Suppose you are working on the language and begin to notice parallels with English, such as "das Buch" = book, "kochen" = to cook, and "suchen" = to seek. These show a consistent relationship between German "ch" and English "k," which is far more meaningful than if book, cook, and seek seemed to align with, say, "ubakr," "kouki," and "zeqqol." With chance finds, of course, it is unlikely that consistent patterns will arise. So even if your list of cognates was still small, the pattern of sound changes could help you realize that perhaps more than chance was at play.
But chance is always a possibility. In fact, false cognates due to chance can be found without too much trouble. In Chinese, "fei" can mean "fee," but there's no evidence that any legitimate relationship is behind this and many other chance parallels. How often can chance lead to a false cognate? Stubbs suggests it is 1% to 3% of the time. OK, but I think it would be very hard to contrive English-Chinese parallels for 1% of either language. But accepting that range, Rogers crunches some numbers to suggest that the 1500+ cognates presented by Stubbs are meaningless. To do this, he considers that the Uto-Aztecan language family has 30 languages and that Stubbs is scanning 3 Old World languages, which greatly increases the potential for finding parallels. Rogers argues that at a 3% rate of chance cognates, we might expect nearly 5,000 chance parallels, making 1,500 completely pathetic. Here's the relevant portion of his paper from pages 255-256 (click to enlarge):

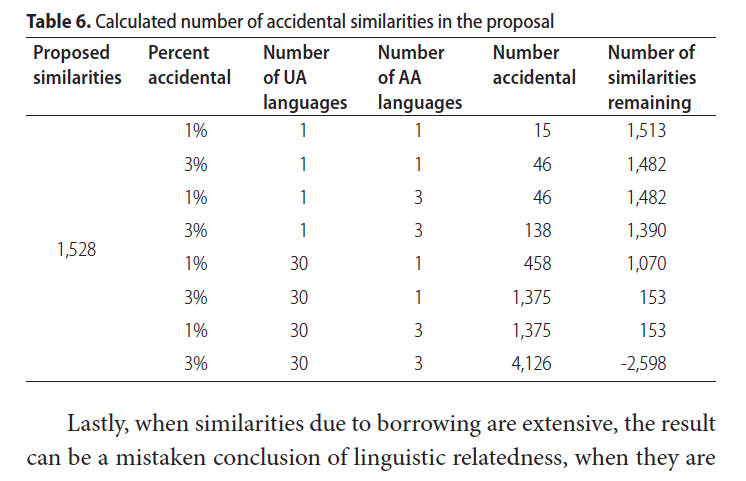

There's clearly something wrong when he reports that 2,598 similarities are expected by chance alone, for that number is the number with a minus sign (i.e., 2,598 less than zero) is the number Table 6 shows remaining after subtracting the actual calculated number of possible false cognates, 4,126, from the number of cognates presented by Stubbs, 1,528. But much more trouble is occurring here than just reporting the wrong sum. This number of over 4,000 false cognates is based on rather spurious math, IMO.
The first additional problem is that Rogers is using the wrong base in calculating potential false cognates. He treats 1,528 as that base, but the base should be the number of words in the language family being considered, which is an even bigger number. But let's assume that Rogers math is correct and that there's a base of only 1,528 Uto-Aztecan words, incorrectly implying that Stubbs is proposing that 100% of the UA vocabulary is related to Egyptian and Semitic. Even in that case, Rogers obliterates any cause for excitement by multiplying the upper limit of 3% chance of a random correspondence by 30 Uto-Aztecan languages and by 3 Old World languages, in other words, 0.03 * 30 * 3 = 2.70, giving 270% of the entire vocabulary being subject to false cognates with Stubb's 3 Old World languages by chance. That's how 1,528 cognates from Stubbs becomes a potential 4,126 false cognates in the crazy math of Table 6. Something is out of touch with reality here.
Part of the problem here is that the 30 languages of Uto-Aztecan are all related, and that Stubbs is not creating an additional entry and claim for each related cognate in each language. Worse than double jeopardy, Rogers would give a false cognate a penalty of 30 * 3 = 90 words to deduct from Stubbs' list. Note that almost each of the 1500+ cognates from Stubbs involve multiple languages and usually involve reconstructed Proto-Uto-Aztecan words; he's not counting a cognate as, say, 15 cognates when half of Uto-Aztecan languages seem to share it, but lists it as one entry.
Further, great weight should be given to cognates that involve Proto-Uto-Aztecan, which would naturally tend to involve multiple modern UA languages. Rogers should consider the high number of cognates that are related to Proto-Uto-Aztecan, where it makes even less sense to conjure up huge numbers of expected false cognates with the multiply-by-30 tactic.
To get a feel for what Stubbs is reporting and how he counts multiple related hits in multiple languages, below is a randomly selected section from Stubbs' more technical book (I scrolled to a random place and then picked a contiguous section that included discussion of the sound change rule under consideration), where you can see for yourself. Many of those two- and three-letter abbreviations in his explanations are abbreviations referring to specific languages, and UACV followed by a word with a leading asterisk refers to a reconstructed Proto-Uto-Aztecan word from his definitive publication on the language, which is used in each of these entries and I believe the majority throughout the book. Here's the excerpt from pages 80-81 of Exploring the Explanatory Power of Semitic and Egyptian in Uto-Aztecan, which can be downloaded at BMSLR.org for free, courtesy of Jerry Grover (click to enlarge):



Sadly, even some highly educated people have jumped on Table 6 and feel that Rogers with his reported gargantuan numbers for expected false cognates (up to 270% of the vocabulary) has provided compelling reasons to dismiss Stubbs' work as meaningless garbage all due to chance alone. You can always find a reason to dismiss something you don't like, but relying on preconceived notions coupled with bad math is not the most accurate way to reinforce your views. These kind of math errors are easy to make, I'll admit, but it's unfortunate that they survived peer review for the Maxwell Institute's publication. What Stubbs gives us requires more thoughtful attention that this. Yes, it's counter to so much that we think we know so it's easy to want to dismiss it, but the data is not readily explained by chance cognates, and the patterns of consistent sound changes add a great deal that Rogers is missing. I hope Rogers will give Stubbs a closer look! I think he missed some significant aspects of the work he criticizes. Hoping for a round 2!
I also have to point out that Rogers' comment on pp. 255-256 about not accounting for the impact of borrowing is quite puzzling. Stubbs is arguing that there was an infusion of ancient languages, not a genetic relationship. Read Stubbs' response on my previous post to get into that issue more fully. But for today, I'm just addressing the issue of Table 6 and its faulty math.
Continue reading at the original source →